Développement Mobile
Mobile Applications: Strategies and Implementation
Description: This course is an introduction to mobile application development. It presents different strategies for mobile development (native, web and progressive web apps, hybrid, MBaaS), along with the associated publishing options, and illustrates two of these strategies through hands-on implementation (currently planned: native development with Android and hybrid development with Flutter).
Learning outcomes: By the end of this course, students will be able to select a mobile application development strategy and develop simple applications using two different approaches.
Evaluation methods: 1h written test
Evaluated skills:
- Development
Course supervisor: Virginie Galtier
Geode ID: SPM-INF-022
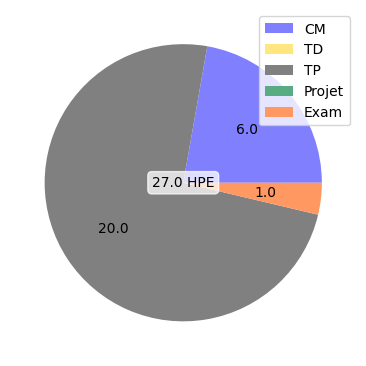
CM:
- introduction : les différentes stratégies pour le mobile 1/2 (1.5 h)
- introduction : les différentes stratégies pour le mobile 2/2 (1.5 h)
- introduction à Android (1.5 h)
- introduction à Flutter (1.5 h)
TP:
- développement natif (3.0 h)
- développement natif (4.0 h)
- développement cross-platform (3.0 h)
- développement cross-platform (4.0 h)
- processus de test et publication (2.0 h)
- processus de test et publication (3.0 h)